
随着 RLHF 成为大模型对齐(Alignment)的核心技术之一,越来越多研究开始探索使用 AI Feedback(RLAIF) 替代昂贵的人类标注,以降低训练成本并提升可扩展性。
本文整理并调研了几种典型的 AI 反馈对齐方法,包括:
- RLAIF:使用 AI 标注器替代人类反馈进行强化学习
- RLAIF-V:通过原子陈述分解与视觉验证提升多模态模型可信度
- Self-Rewarding LLM:模型自生成数据并进行自评估形成训练信号
- Constitutional AI / CCAI:通过原则或公众输入指导模型行为
同时记录了这些方法在 偏好数据构造、LLM-as-a-Judge、DPO 训练 等关键环节中的实现思路。
本文作为一份 RLAIF 系列技术阅读笔记,重点总结不同 AI Feedback 方案的核心流程与差异。
RLAIF: SCALING REINFORCEMENT LEARNING FROM HUMAN FEEDBACK WITH AI FEEDBACK
https://openreview.net/pdf?id=AAxIs3D2ZZ
prompt设计
1 | prompt前缀 |
偏好数据出现顺序
先1后2,先2后1,取均值
Direct RLAIF
没有先训练奖励模型,而是直接使用 AI 标注器对生成内容进行评分,将这些评分视作奖励信号。
具体来说,AI 标注器根据某些标准(如准确性和简洁性)对每个生成的响应进行量化评分(从1到10),然后将这些评分转化为一个标准化的奖励信号。这些标准化后的数值被直接用于指导目标模型的强化学习过程。

RLAIF-V: Open-Source AI Feedback Leads to Super GPT-4V Trustworthiness
CVPR 2025 Paper: RLAIF-V — Open-Source AI Feedback Leads to Super GPT-4V Trustworthiness
使用大模型生成多个响应,通过混淆策略生成偏好对。
分解(Divide)
我们提示大型语言模型将响应 y 分解为原子陈述:
{c1, c2, ..., cm}
通过提取事实而排除意见和主观陈述,以便分别进行评估。
解决(Conquer)
为了评估陈述 c 的可信度(例如“时钟显示约11:20。”),我们首先将其转换为极性问题,例如:
时钟显示约11:20吗?
这样可以用简单的“是”或“否”回答,而不引入额外内容。
对于每个原子极性问题,我们让开源 MLLM 生成同意和不同意的信心作为该陈述的分数:
sc = (pyes, pno)
其中:
pyes是回答“是”的概率pno是回答“否”的概率
较高的 pyes 分数表明标注模型认为该陈述更可信。
通过这种方式收集到的分数,通常比直接对完整响应做整体评估更准确,因为原子陈述在结构和内容上都更简单。
结合(Combine)
在获得每个陈述的质量评估后,最终将它们组合为整个响应的分数。
对于每个响应,我们将满足 pno > pyes 的陈述数量记为 nrej,用于衡量标注模型识别出了多少不正确的陈述。
我们使用 -nrej 作为响应的最终分数 S,其中较高分数表示内容的不正确性更少。
给定每个响应的分数,我们现在可以构建用于训练的偏好数据集。对于每个指令 x,保留所有响应对 (y, y'),使得 S > S',并选择较高分数的响应 y 作为首选响应。
为了节省训练成本,我们随机抽取每个指令最多 2 个对,并发现这种过滤过程仅导致轻微的性能下降。
为了防止潜在的长度偏差,我们在训练前丢弃 yw 过短的对,确保 yw 和 yl 的平均长度差异小于一个词。
Specific versus General Principles for Constitutional AI
https://arxiv.org/pdf/2310.13798
Collective Constitutional AI: Aligning a Language Model with Public Input
https://dl.acm.org/doi/pdf/10.1145/3630106.3658979
公众参与:CCAI 通过一个多阶段的过程,将公众意见纳入语言模型的开发过程。这个过程包括
识别目标群体、收集公众原则、训练和评估模型。
Self-Rewarding Language Models
https://openreview.net/pdf?id=0NphYCmgua
构建一个模型,旨在同时具备两种技能:
- 指令遵循:给定一个描述用户请求的提示,生成高质量、有帮助且无害的响应的能力。
- 自我指令创建:生成和评估新的指令遵循示例并将其添加到自己的训练集中的能力。
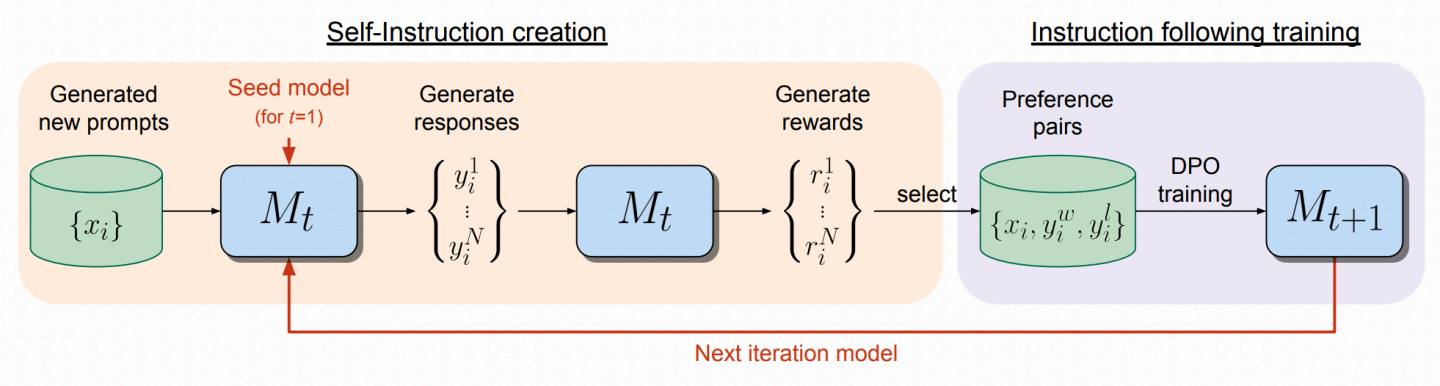
- 种子指令遵循数据
我们得到了一个人工创作的(指令提示,响应)通用指令遵循示例集,我们以监督微调(SFT)的方式进行训练,从一个预训练的基础语言模型开始。
随后这部分数据被称为 指令微调(IFT)数据。 - 生成新提示
我们使用少量样例提示生成一个新的提示x_i,从原始种子 IFT 数据中采样提示。 - 生成候选响应
我们为给定的提示x_i从模型中生成N个不同的候选响应:{y^1_i, y^2_i, ..., y^N_i}
生成方式使用采样策略。 - 评估候选响应
最后,我们使用同一个模型的 LLM-as-a-Judge 能力来评估其自己的候选响应。
评分范围:r^n_i ∈ [0, 5]
(具体提示见附录 6)。 - AI 反馈训练
执行自我指令创建过程后,可以通过额外的训练示例增强种子数据,我们将其称为 AI 反馈训练(AIFT)数据。
构建偏好对,即形式为:(指令提示x_i,优胜响应y^w_i,失败响应y^l_i)的训练数据。
为了形成优胜和失败对,我们从N个评估过的候选响应中选择 评分最高 和 评分最低 的响应(见第 2.2 节)。
如果它们的得分相同,则丢弃该对。
这些样本可以用于 偏好微调算法训练(DPO)。

