
在多模态大模型的发展中,视觉语言模型(LVLMs)显示了强大的视觉理解能力,但也面临着严重的Hallucination,特别是在多对象识别任务中。本篇笔记基于《Multi-Object Hallucination in Vision-Language Models》,深入探讨了LVLMs在同时处理多个对象时产生的幻觉现象及其原因。本篇笔记介绍了论文提出的“基于识别的对象探测评估”(ROPE)方法,这是一种全新的评估协议,用于精确分析模型在多对象场景下的表现。此外,我还总结了作者关于数据分布、模型特性等如何影响幻觉行为的关键发现。通过这篇笔记,希望能为多模态大模型的幻觉问题提供启示,为未来的改进方向带来更多思考。
Abstract
问题背景:LVLMs在多对象场景中容易产生幻觉,例如识别出图像中不存在的对象。
研究方法:提出了ROPE协议,用于多对象幻觉评估,关注对象类别分布并消除指代歧义。
主要发现:
- 多对象关注比单对象更易导致幻觉。
- 对象类别分布(object class distribution)会影响幻觉行为。
- 幻觉行为受到数据的显著性、频率和模型内部特性影响。
Introduction
背景与发展:随着大型语言模型(LLMs)的发展,越来越多的研究致力于将LLMs应用于视觉语义理解,催生了大量的视觉语言模型(LVLMs)。这些模型无论是否通过“锚定数据”进行显式训练,都展示了良好的视觉实体理解能力。
主要问题 - 对象幻觉:尽管LVLMs在多种任务中表现优异,但在处理图像内容时,常会出现“对象幻觉”现象,即识别出图像中不存在的对象。最早的对象幻觉是在多对象图像描述任务中发现的,但当前的评估基准主要关注单一对象类别,忽略了多对象场景的复杂性。
当前评估的局限性:
- 多对多映射问题:对象与类别并非一一对应,而是多对多映射。例如,“苹果”可能对应多个对象,因此模型能正确生成一个对象类别并不代表其无幻觉。
- 多对象识别难度:相比简单的单对象是/否判断,多对象识别任务更具挑战性,因为不同对象间的常见关联会导致模型产生误判。例如,“刀”和“叉子”常在一起出现,这种关联可能导致模型在识别多个对象时出现幻觉。
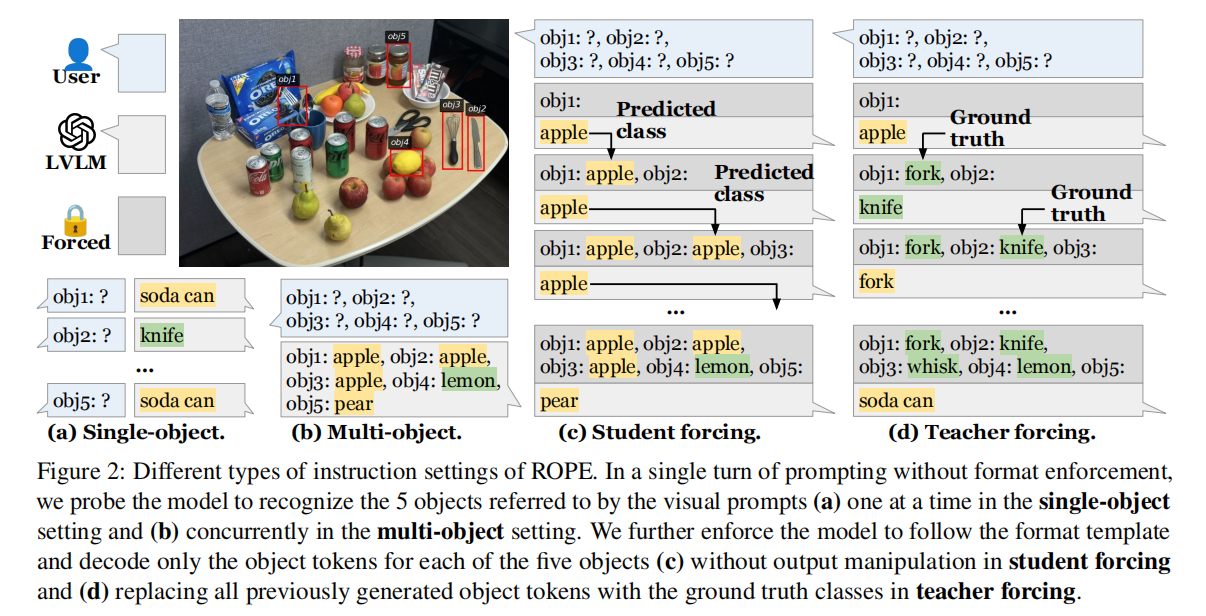
研究目标与方法:本文研究多对象幻觉问题,分析模型在关注多个对象时如何产生误判及其原因。为此,作者提出了Recognition-based Object Probing Evaluation(ROPE),使用视觉指代提示并避免多重参照歧义。
ROPE的主要特性:
- 自动化评估:ROPE通过格式化输出进行自动评估,无需黑箱模型或人工参与。
- 对象类别分布考虑:在测试中,ROPE根据图像中的对象类别分布划分为4个子集(随机、同类、异类、对抗分布),以更全面地评估LVLMs的多对象识别能力。
关键发现:
- LVLMs在多对象任务中比单对象任务更容易出现幻觉。
- 不同的对象类别分布会影响模型的幻觉行为,可能导致模型依赖虚假关联。
- 幻觉行为受数据特定因素(显著性、频率)和模型特性影响。
Related Work
Visual Prompting
概念:视觉提示是一种通过视觉标记或视觉文本向模型提供线索的方法,LVLMs通过视觉提示可以实现零样本的视觉理解。
方法演变:从早期基于微调的方法(如SoM)到无需训练的新方法,视觉提示在模型中直接添加视觉标记以减少歧义。
增强方式:近期的工作通过多种覆盖视觉提示和显式视觉指针的方式,进一步提升了模型的视觉提示效果。
应用于幻觉评估:在多对象幻觉的评估中,视觉提示帮助避免文本描述中的歧义,特别是在相同类别的多对象情境下。
Object Hallucination
缓解方法
- integrating an external object detector:引入外部模型辅助识别真实对象。
- visually grounded visual instruction tuning:通过视觉锚定数据增强指令微调。
- reinforcement learning:使用RL来引导模型生成更准确的内容。
- iterative refinement:多次修正输出,逐步提高准确性。
- adapting the decoding strategies:改变模型的解码方式减少幻觉。
ROPE基准特点
- 对象类别分布考虑:测试时关注图像内对象类别分布,这一影响尚未被现有研究充分探索。
- 视觉指代:使用视觉提示(如标记框)避免歧义,特别是在相同类别的多对象场景中。
- 自动化评估:无黑箱模型或人工参与的自动化评估。
Recognition-based Object Probing Evaluation (ROPE)
Task Setup
Problem Definition
ROPE协议中的每个样本由四元组 ${I, L, ⟨p_1, · · · , p_n⟩, ⟨o_1, · · · , o_n⟩}$ 组成:
- 图像 $I$:包含至少 $n$ 个对象;
- 自然语言指令 $L$:指定识别任务,包括 $N$ 个候选对象类别 $c_1,⋯,c_N$;
- 视觉提示 $p_1,⋯,p_n$:每个提示查询图像中的一个对象;
- 对象类别 $o_1,⋯,o_n$:作为任务答案。
在此研究中,我们构建了一个包含 $N=50$ 个类别和 $n=5$ 个对象的数据集,模型需在50个候选类别中识别出5个对象。
Language Instruction Prompts
- Default:让模型同时识别5个对象。
- Student-Forcing:强制模型严格遵守格式,避免格式错误。
- Teacher-Forcing:提供正确的上下文条件,评估模型的上限性能。
Dataset Construction
数据集来源:基于现有的全景分割数据集(如MSCOCO Panoptic和ADE20K),选择包含多种类别和实例级语义标注的图像数据。
分布划分
- 同类分布(Homogeneous):5个对象均为同一类别, 例如AAAAA
- 异类分布(Heterogeneous):5个对象均为不同类别, 例如ABCDE
- 随机分布(In-the-Wild):对象类别分布混合,随机选择5个对象。
数据污染与分集:根据图像是否在指令微调中出现,将数据集分为 Seen 和 Unseen 图像,以研究模型在不同训练数据环境中的幻觉表现。最终测试集分为8个文件夹,以实现更细致的评估。
Experiments and Results
LVLM Baselines
基准模型选择:
- 基础LLM规模:选择了多种规模的LVLMs(从6B到34B)。
- 训练数据差异:基准模型包含使用不同数据(对话数据、锚定数据)进行微调的模型。
- 机制锚定模型:包括通过专门设计机制接收视觉提示的模型。
提示可视化方法:
- 机制锚定模型:使用默认机制处理视觉提示。
- 其他模型:在图像上使用红色边界框和带对比度的视觉文字显示提示内容。

