
在这篇笔记中,我详细记录了关于论文《ShareGPT4V: Improving Large Multi-Modal Models with Better Captions》的阅读心得。该论文通过引入一个创新性的高质量图像描述数据集——ShareGPT4V,在大规模多模态模型中实现了显著性能提升。ShareGPT4V数据集包含超过百万条详细且多样化的图像描述,与现有的数据集相比,不仅增强了模型的视觉-文本模态对齐效果,还显著提高了在多个基准测试中的表现。
Abstract
研究背景:多模态模型的发展受限于高质量图像-文本数据的不足,模态对齐难度大。
解决方案:提出了ShareGPT4V数据集,包含120万条丰富多样的高质量描述性标签,覆盖广泛的信息维度。
数据来源:数据集由GPT4-Vision生成的10万条高质量标签扩展至120万条,通过一个强大的标签模型实现扩展。
性能提升:在SFT阶段,通过替换现有数据集中的部分标签,ShareGPT4V显著提升了多模态模型在MME和MMBench基准测试中的表现。
创新点:在预训练和SFT阶段均使用了ShareGPT4V数据,形成了性能优越的多模态模型ShareGPT4V-7B。
贡献:该项目公开资源,为多模态模型研究领域提供了新的、重要的资源和支持。
Introduction
该部分详细介绍了多模态模型在模态对齐中的问题,并提出了高质量描述数据集作为解决方案。通过实验验证,展示了ShareGPT4V数据集在提升模型性能方面的优势,突显了高质量图像-文本数据在多模态学习中的重要性。同时,开发的ShareGPT4V-7B模型在多个基准测试中取得了领先成绩,证明了该数据集的实际应用价值。
背景:近年来多模态LLMs迅速发展,模型通常遵循预训练和监督微调的两阶段训练流程。
问题:现有LMMs在视觉与语言模态对齐方面表现欠佳,主要因为缺乏高质量的图像-文本数据对。
实验验证:使用GPT4-Vision生成的详细描述替换部分SFT数据,对多个LMM的性能进行了重新评估,发现即使替换比例较低,也能显著提升模型性能。
ShareGPT4V数据集:包含10万条高质量描述和120万条由描述模型生成的描述,涵盖多种图像信息。该数据集帮助构建了性能优越的ShareGPT4V-7B模型。
贡献:
- 指出低质量描述对模态对齐的负面影响,并通过实验验证。
- 提出并开放了高质量的ShareGPT4V数据集。
- 利用该数据集开发了性能出色的ShareGPT4V-7B模型。
Related Work
图像-文本数据提升:
改进数据描述质量的研究多集中在重写和过滤合成描述上,如LaCLIP和VeCLIP,然而仍面临合成描述质量低的问题,易引发幻觉现象。
LLaVA尝试将人类标注短描述输入LLM中,但依赖大量标注数据,未能真正让模型“看到”图像,易产生误导性内容。相较之下,GPT4-Vision直接生成高质量描述,有助于提高LMMs的描述准确性。
ShareGPT4V Dataset
ShareGPT4V Data Collection
- Data sources:
使用GPT4-Vision从多个数据源生成10万条高质量描述。
数据来源多样,包括检测图像、分割图像、复杂文本图像及网络图像。
Prompt Design:
设计了基础提示词和特定提示词,以确保描述不仅包含基本属性信息,还涵盖相关的知识信息和美学评价。Quality Verification:
通过实验验证了我们的描述对提升LMMs在SFT阶段性能的显著效果,表明高质量描述的重要性。
ShareGPT4V-PT Data Generation
- ShareGPT4V-PT 数据生成:
使用GPT4-Vision生成的10万条描述微调了一个新的模型——Share-Captioner。
Share-Captioner能够生成一致性强、内容相关的高质量描述,无需专门的提示词。
从公开数据集中选取了120万张图像,并使用Share-Captioner生成对应描述,耗费了44天的A100 GPU计算资源。
Qualitative Analysis:
Share-Captioner生成的描述与GPT4-Vision相似,验证了模型在描述生成过程中的效果。

Quantitative Analysis:
通过志愿者评价验证了Share-Captioner与GPT4-Vision的描述质量相当。
ShareGPT4V-7B Model
本节展示了ShareGPT4V-7B模型的架构和训练方法,其核心目的是验证ShareGPT4V数据集在提升LMM模态对齐能力方面的效果。通过将高质量的图像-文本对数据用于预训练和微调,作者展示了ShareGPT4V数据集在模态对齐上的显著提升,而该模型的结构相对简洁、轻量,意在聚焦数据集的价值。
Model Architecture
ShareGPT4V-7B模型基于LLaVA-1.5设计,包括vision encoder、projector和LLM三部分,采用轻量级的7B规模模型。
该模型主要用于验证ShareGPT4V数据集的有效性,展示其在模态对齐方面的提升效果。
Pre-Training
使用ShareGPT4V-PT数据进行预训练,通过微调视觉编码器、投影模块和大语言模型,使模型能够更好地理解图像-文本对的关系。
这一设计确保了模型能够充分利用高质量描述的细节信息,与描述中的视觉嵌入相匹配。
Supervised Fine-Tuning
利用LLaVA-1.5的基础数据集进行SFT,并替换了其中23k条描述为ShareGPT4V的高质量描述,以便验证高质量数据的提升效果。
在SFT阶段冻结了视觉编码器,仅微调投影模块和语言模型,以提高训练效率并保持对比的公平性。
Experiments
Benchmarks
ShareGPT4V-7B在11个覆盖广泛视觉问答任务的基准测试中表现出色,特别是LLaVA、MME、MMBench、SEED和传统VQA基准测试。
Quantitative Comparison 定量对比
ShareGPT4V-7B在11个基准测试中9项表现最佳,超越了使用更大数据和参数的LMMs,特别是在详细描述、复杂推理和低层次感知任务上表现突出。
该模型证明了在7B的轻量参数下,凭借高质量的描述数据,能够显著提升模型的模态对齐和任务完成效果。
Multi-modal Dialogue
多模态对话示例展示了ShareGPT4V-7B在图像细节理解和美学评估中的能力,进一步支持高质量描述数据的价值。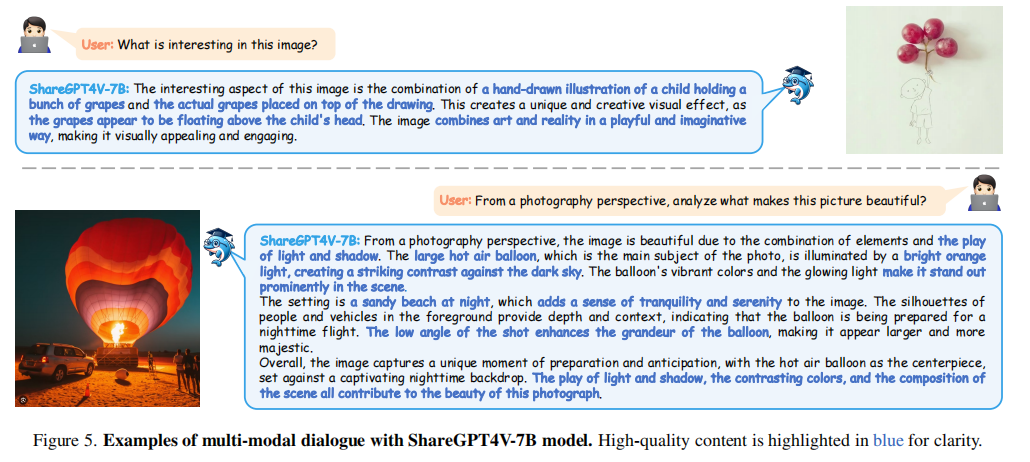
Ablations
数据集的有效性:在SFT和预训练阶段使用ShareGPT4V数据集都带来了显著的性能提升,特别是预训练阶段使用高质量描述有助于显著提高模型的感知能力。
描述质量:通过与基准BLIP生成的数据对比,证明了高质量描述在提高模型性能和模态对齐方面的重要作用。
描述数量:实验显示即使使用100K高质量描述也能显著提高模型性能,且在1000K数据量后性能趋于饱和,说明高质量数据在模态对齐中的高效性。
ViT块解锁:在预训练阶段解锁视觉编码器后半部分的transformer块能够更好地促进模态对齐,进一步提升了模型在各基准测试中的表现。
Conclusion
该数据集凭借120万条详细、丰富的描述,为LMMs的模态对齐和性能提升提供了有力支持,超越了现有数据集的内容广度和深度。实验验证了其在SFT和预训练阶段的有效性,而ShareGPT4V-7B模型的优越表现进一步表明了高质量数据对多模态模型的提升潜力。

