在多模态学习和图像理解领域,传统的基准测试多聚焦于单图像场景,忽略了多图像信息整合的复杂性。《MUIRBENCH: A Comprehensive Benchmark for Robust Multi-image Understanding》一文引入了MUIRBENCH,一个专为评估多图像理解能力而设计的全新基准,涵盖了丰富的图像关系和任务类别。本篇笔记将深入解析MUIRBENCH如何推动多模态大模型在多图像推理上的进展,并揭示现有模型的不足之处与未来改进的方向。
Abstract
MUIRBENCH 基准的特点:
- 多样性:包含12种任务和10类图像关系类型,适用于多图像理解能力的全面评估。
- 数据量:11,264张图像和2,600道多选题,确保评估的覆盖面。
- 成对设计:每道题都包含可解答与不可解答对,以确保模型的准确性和稳健性测试。

实验结果:
- 高级模型的挑战性:即便是高级多模态模型GPT-4o和Gemini Pro,准确率仍低于理想值,表明多图像理解任务的高难度。
- 开源模型的局限性:仅基于单图像训练的开源模型在多图像任务中泛化能力不足,准确率偏低。
重要性与未来发展方向:
- MUIRBENCH为多模态大模型提供了一个超越单图像处理的机会,揭示了需要提升多图像理解能力的领域,为未来多模态模型的改进提供了方向。
Introduction
人类的多图像理解优势:
人类擅长整合多幅图像以获取完整、整体的世界观,如通过卡通系列图像讲故事、比较图表以获得洞见等。
多图像输入可以克服单图像的分辨率限制,使视觉理解更加全面。
多模态LLM的现状和挑战:
尽管多模态LLM在单图像任务中表现优异,但当前评估方式局限于单图像理解,未能充分测试模型的多图像理解能力。
现有的基准未能全面覆盖多图像任务的复杂性,限制了模型在高级多模态理解中的潜力。
MUIRBENCH的设计与贡献:
数据规模:MUIRBENCH包含11,264张图像和2,600道题,覆盖12种多图像任务和多种图像关系类型。
成对设计:每道题都包含一个不可解答的对应项,确保了模型在多图像理解中的可靠性。
精细注释:附有丰富的图像位置和类型注释,有助于模型性能的细致分析。
实验结果和结论:
当前最强的多模态LLM在多图像任务中的表现不及人类,且在不可解答问题上差距更大。
基于单图像训练的LLM在多图像情境下表现有限,揭示了提升多图像理解能力的迫切需求。
Related Work
该部分明确了当前多模态LLM评估和模型发展中的不足。现有基准大多聚焦于单图像场景或不同的多模态任务,未能全面覆盖多图像理解场景,尤其是在多视角、多关系和推理复杂性方面的需求。同时,早期多模态LLM的单图像训练限制了模型在多图像推理方面的拓展。
多模态理解基准的现状:
当前基准大多集中于单图像评估,无法全面测试模型的多图像理解能力。
一些基准涉及视频或情境学习,但其核心任务与多图像理解有所不同。
MANTIS-Eval和DEMON等基准开始探索多图像推理,但覆盖的关系和推理类型有限,缺乏稳健性。
多模态大模型的发展:
早期的多模态LLM多基于单图像数据训练,未考虑多图像理解的复杂性。
随着MMC4和OBELICS等多模态语料的应用,一些模型可以处理多图像生成任务,但在多图像推理方面尚未完全验证其效果。
指令微调模型在某些任务中表现出多图像输入的初步能力,但多关系和多任务推理能力的探索依然不足。
MUIRBENCH
概述
- MUIRBENCH的设计原则:
全面性:包含12种任务和10种图像关系类型,支持模型的多视角、多关系评估。
稳健性:采用成对设计,每道题目都配备一个不可解答项,确保模型在现实情境中的可靠性。
- 任务类别:
动作理解(ACTION UNDERSTANDING):评估模型按时间顺序理解连续图像并将其与相应动作匹配的能力。
属性相似性(ATTRIBUTE SIMILARITY):评估模型在多张图像中识别给定属性的能力。
卡通理解(CARTOON UNDERSTANDING):评估模型理解卡通图像中故事内容的能力。
计数(COUNTING):评估模型在多张图像中计数特定物体数量的能力。
图解理解(DIAGRAM UNDERSTANDING):评估模型理解图解信息的能力。
差异发现(DIFFERENCE SPOTTING):评估模型在多张图像中识别差异的能力。
地理理解(GEOGRAPHIC UNDERSTANDING):评估模型理解地图和地理特征推理的能力。
图文匹配(IMAGE-TEXT MATCHING):评估模型理解文本片段含义并与对应视觉内容匹配的能力。
排序(ORDERING):评估模型根据文本描述对一系列图像排序的能力。
场景理解(SCENE UNDERSTANDING):评估模型理解由多个监控图像构成的场景的能力。
视觉定位(VISUAL GROUNDING):评估模型在多张图像中定位特定物体并获取信息的能力。
视觉检索(VISUAL RETRIEVAL):评估模型检索包含相同建筑物图像的能力。
- 数据的多样性:
涉及10种图像关系(如叙事、多视角、时间序列)和多种图像类型,增加了基准的复杂性和真实度。
- Robust Evaluation:
在现实场景中,用户的问题不一定总是可解答的。
使用多种方法手动创建不可解答项,以模拟用户在现实中的提问情况,增强评估的可信度和实用性。
Data Collection
可解答数据收集策略:
使用三种数据来源:现有数据集 existing datasets、衍生数据 dataset derivations(通过多种策略(如问题生成、选项重写和单图像问答组合等)将数据转换为MCQA格式)和新收集的数据newly collected data。
新数据特别关注地理理解和视觉检索等任务,以弥补现有数据的不足。
不可解答数据的生成方法:
图像替换或重新排序:扰乱图像关系,使问题无法解答。
问题修改:使问题与图像和选项不兼容。
选项替换:创建没有正确答案的场景。
质量控制措施:
自动检查:确保数据格式、答案、图像共指和图像可访问性。
人工检查:由专家审查,排除不清晰或容易混淆的数据。
Experiments
实验结果凸显了MUIRBENCH对当前多模态LLM的挑战性,同时揭示了多图像任务中的独特需求。尽管单图像输入模型尝试泛化到多图像任务,但效果不佳,这表明多图像理解能力的开发需依赖专门的训练数据和策略。该实验进一步验证了MUIRBENCH作为多模态LLM测试平台的价值,并为未来提升模型的多图像推理能力指明了方向。
Experimental Setup
涵盖多种多模态LLM,包括专为多图像设计的模型和为单图像设计的模型。
使用标准评估设置,将不支持多图像输入的模型图像拼接为单一输入。
Main Results
整体表现:先进MLLM在MUIRBENCH上的准确率普遍不高,甚至某些模型在特定任务上的表现不及随机猜测。
优势与劣势任务:模型在图文匹配、视觉检索和图解理解上表现较好,但在多图像排序和视觉定位上表现较差(这些任务需要理解完整的多图像上下文,并在图像和模态之间进行更复杂的推理过程),说明多图像任务中的复杂推理仍是难点。
单图像模型的局限:单图像输入模型难以泛化到多图像任务,而多图像输入模型得益于多图像训练数据和过程,表现更好。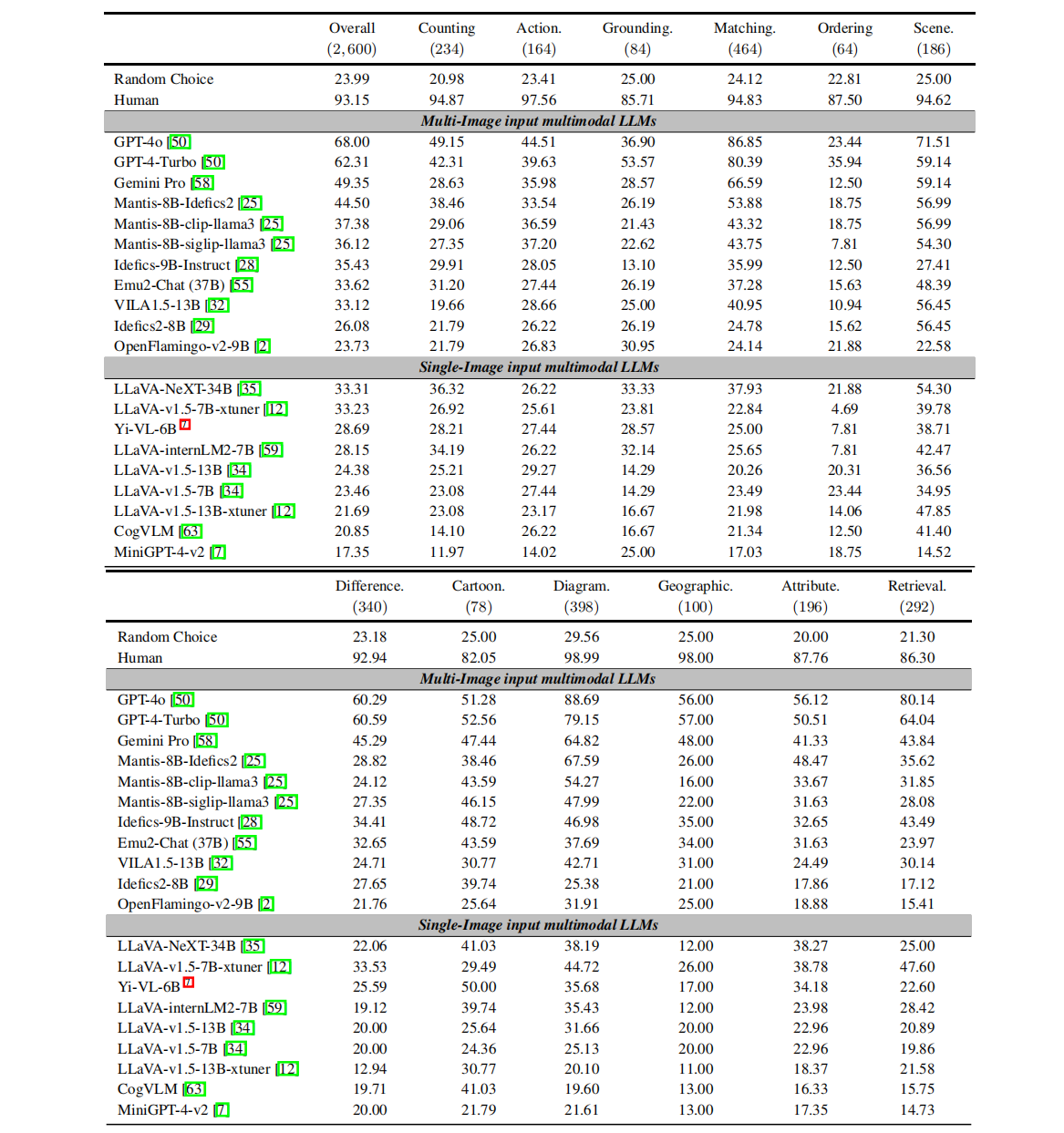
Analysis
不可解答问题的表现差异:
所有模型在不可解答集上的表现明显下降,模型在不可解答情境下往往倾向于随意作答,而非选择“放弃”。
GPT-4o的主要错误类型:
细节捕捉不足:26%的错误因未能准确捕捉图像细节而产生。
计数和推理不准确:占20%,主要表现在物体计数错误和推理不准确。
逻辑推理错误:占18%,表现为逻辑推理不正确。
跨场景识别困难:14%的错误源于未能在不同场景识别相同物体。
意图推断失败:12%的错误在于未能从图像序列中推断出意图。
模型的幻觉问题:
面对不可解答问题时,模型倾向于选择看似正确但实际错误的答案,而非选择“放弃”,表明模型在不可解答情境下的局限性。
Conclusion
实验发现:
现有的20个多模态LLM,包括GPT-4和Gemini Pro,表现出显著的局限性,难以在多图像场景中与人类表现相匹敌。
模型在不可解答问题上的表现尤为薄弱。
Appendices
可解答数据的来源和整理
现有数据集:如GeneCIS和SeedBench,专注于特定多图像推理方面或包含少量多图像数据,每个数据集最多抽取200个实例。
衍生数据集:如NLVR2、ISVQA,通过问题和选项的重新设计转化为MCQA,每个数据集抽取200个实例。
新收集数据:补充了缺乏的任务和图像类型,四个新数据集(HistoricalMap、UnivBuilding、PubMedMQA、SciSlides)共占37.5%。
不可解答实例的生成策略
图像替换或重新排序:24.2%的不可解答实例通过调整图像关系生成。
问题修改:35.3%通过使问题与图像或选项不兼容生成。
选项替换:40.5%通过更改选项以确保没有正确答案生成。
元数据标注
图像关系:手动标注,重要性较高,影响模型的多图像推理能力。
任务和图像类型:部分来自现有数据,缺失部分手动补充。
图像数量和位置:自动标注,确保标注的准确性。
质量控制
自动检查:确保数据格式、答案、元数据准确性以及图像的可访问性。
人工检查:排除不清晰或有误的数据,最终保留了86.3%的实例。
Experiment Setting Details
Model Prompts
1 | Question: {QUESTION} |
Evaluation Tool
工具首先检测直接答案索引,如未找到则匹配选项内容。
若无匹配,随机选择一个答案;若多个答案有效,选择最先出现的。
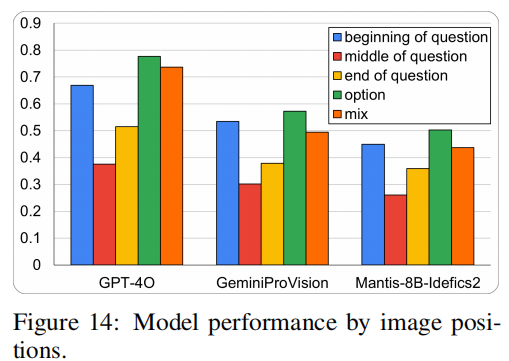
图像位置与错误率的关系
当图像作为选项呈现时,模型准确率最高;当图像位于问题中间时,错误率最高。
可能原因包括:中间或结尾位置的图像打断上下文流,增加了处理复杂性。
训练过程中,模型可能较少接触到图像在中间位置的情况。