
本篇阅读笔记梳理了《Img-Diff: Contrastive Data Synthesis for Multimodal Large Language Models》这篇论文的核心内容。论文提出了一个名为 Img-Diff 的数据集,专注于通过生成具有“物体替换”特征的相似图像对,来提升多模态大模型在细微图像差异识别任务中的表现。本篇笔记详细记录了论文中的数据集构建方法、对比学习的创新性应用,以及 Img-Diff 在视觉问答和图像差异识别基准测试中的显著提升效果。
Abstract
数据集介绍: 引入名为 Img-Diff 的新数据集,提升 MLLM 对细粒度图像差异的识别能力。
方法:
利用 Stable-Diffusion-XL 模型生成突出物体替换的相似图像对
采用 Difference Area Generator 检测物体差异区域
通过 Difference Captions Generator 生成详细的差异描述。
数据集特性: 尽管数据集规模较小,但具备高质量,聚焦 object replacement。
Introduction
本研究的新方向: 提出了新的 Img-Diff 数据集,生成高度相似但物体细微差异的图像对,要求模型识别图像对之间的差异区域,并通过差异的高质量文本描述学习细粒度识别能力。
数据集的应用与评估: 将 Img-Diff 集成到现有 LLaVA-1.5 和 MGM 原始视觉指令微调数据集中,对模型进行微调后在多项基准测试中表现出显著性能提升。
Background and Related Works
这一部分概述了多模态大模型领域在模型架构、数据集和图像差异描述方面的最新进展和现有方法的局限性。与传统图像描述或识别任务相比,图像差异描述要求更高的细粒度特征识别能力。本研究通过引入新型数据集 Img-Diff,推动了 MLLM 在图像差异识别和图像描述上的表现,展示了数据驱动的探索方向在细粒度图像分析中的潜力。
多模态大语言模型(MLLM)
两个关键影响因素: 模型架构和数据集质量。
代表模型:Flamingo、BLIP-2、Qwen-VL 等采用 CLIP 特征提取,LLaVA 和 MGM 使用投影接口。
数据集策略: 提高预训练图文对数据和改进视觉指令微调数据,后者有助于应对 VQA 等任务。
Datasets on Image Differences
现有数据集:如 Spot-the-Diff、CLEVR-Change、Birds-to-Words 等,通过成对相似图像和差异描述来支持图像差异研究。
生成模型应用: 例如 InstructPix2Pix 结合图像编辑技术生成差异数据,并由 GPT-3 描述编辑内容。
本研究数据集: 采用 Prompt-to-Prompt 技术和 Stable-Diffusion-XL 生成相似图像对,在生成过程中增加了多个过滤步骤以确保数据质量
Models for Image Difference Captioning 图像差异描述(IDC)模型
IDC 专注图像细微变化的描述,传统方法使用 LSTM 和 Transformer 等网络。
新模型:如 VIXEN 利用 MLLM 生成图像差异描述,利用 CLIP 提取差异特征。
The Curation of Img-Diff
Overview
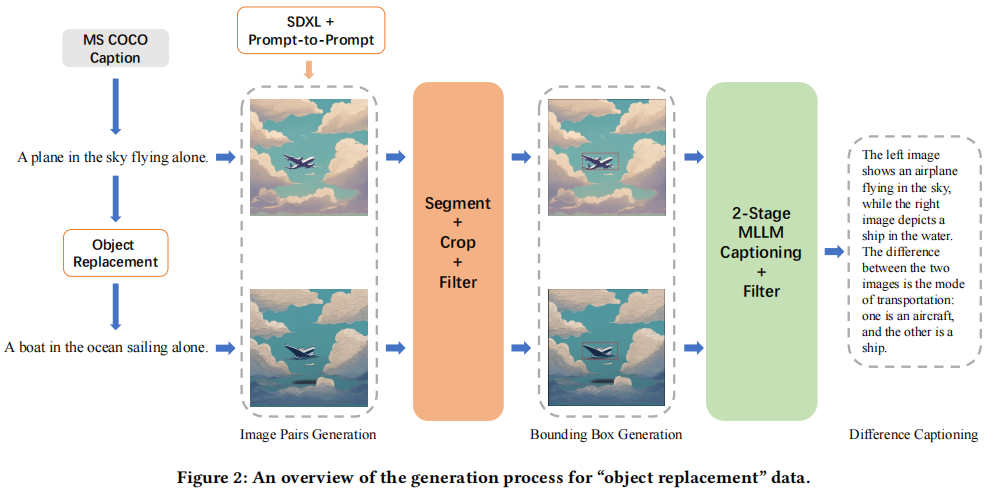
- 通过对比学习原则,生成 MLLM 图文数据,聚焦图像对中的物体替换。
- 生成 object replacement 数据的过程可分为三个主要部分。
2.1. 创建相似图像并构成 Image Pairs
2.2. Difference Area Generator 提取包含图像对中物体差异的边界框区域
2.3. Difference Captions Generator 使用 MLLM 为含有物体差异的区域生成描述性文本,并创建问题-答案对 - 多重过滤操作确保数据质量,组件在 Data-Juicer 中实现,便于复现。
Image Pairs Generation
过程:获取 MS COCO 图像描述,用 Vicuna-1.5-13B 生成物体替换描述对。
使用更高级的 Stable-Diffusion-XL 和 Prompt-to-Prompt 技术,生成少量物体被替换的相似图像对。
整体框架图见原论文figure 2,具体数据示例见附录 C。
Difference Area Generator
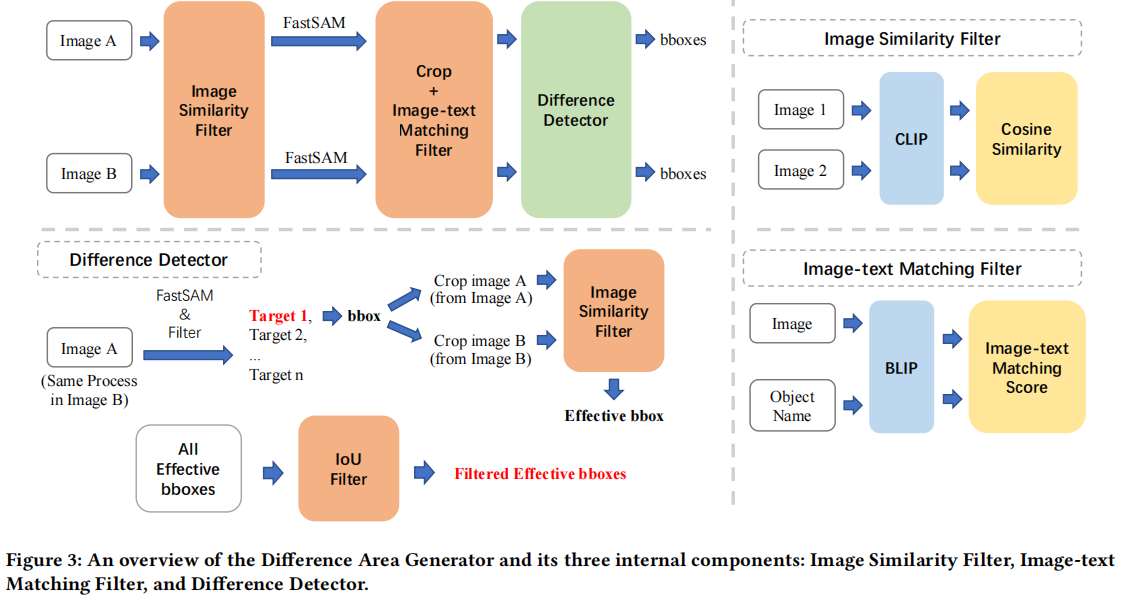
该阶段流程:
- 用 Image Similarity Filter 获取相似但不完全相同的图像对
- 用 FastSAM 对每张图像进行图像分割
- 根据分割获得的边界框信息裁剪图像,通过 Image-text Matching Filter 筛选出有效物体的裁剪子图
- 用 Difference Detector 判断图像对的边界框区域是否确有差异,并进行 IoU 过滤,去除重叠的边界框。
- 最终获得有效的边界框信息

Image Similarity Filter
根据相似度对图像对进行筛选。
通过计算图像对的余弦相似度,确保图像对在视觉上高度相似但非完全相同。
用于生成流程中的两个阶段:最初的图像筛选和裁剪后的子图筛选。
最初的筛选不用多说,第二次的使用是为了过滤没有差异的子图对(两张image只有很小的一块 object 不同)
Image-text Matching Filter
判断图像中是否包含有效物体(即被替换或替换的物体)
使用图文匹配分数筛选出包含有效物体的图像区域。
在裁剪子图后,判断这些区域是否包含被替换的物体。
Difference Detector
最终判断子图区域的差异是否显著,并通过 IoU 去除重叠的边界框,确保只保留包含显著差异的区域。
Difference Captions Generator
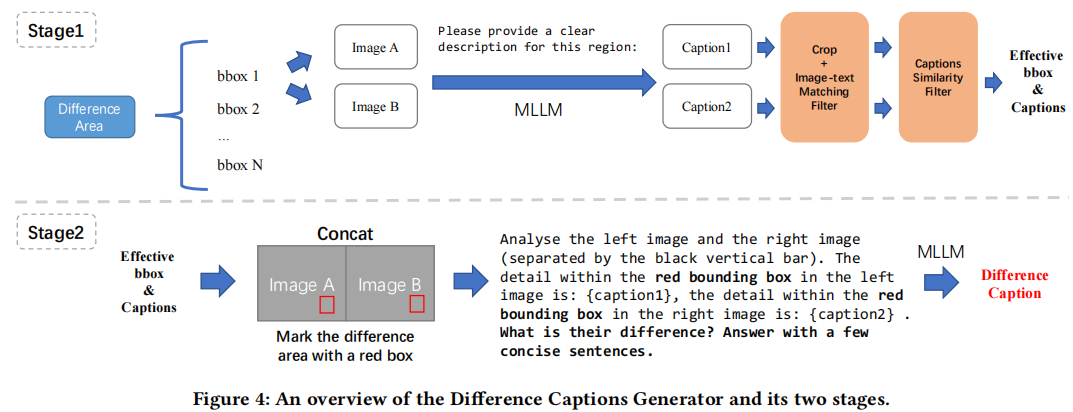
目的:生成图像对中边界框区域的差异描述。
注意: 一对图像可能包含多个差异区域,因此用红框标记待定区。
过程分为两个阶段:
- 生成边界框区域的内容描述,并通过 Image-text Matching Filter 和 Captions Similarity Filter 筛选出有效的边界框和描述
- 使用内容描述和标红框的图像生成差异描述
Stage1: Object Labeling & Filter
选取相似度最低的 N 个候选边界框区域(N=5)。
使用 LLaVA-NEXT 生成区域内容描述,应用 Image-text Matching Filter(检测区域内容与描述是否一致)和 Captions Similarity Filter(用 CLIP 计算描述的余弦相似度,评估两个描述是否存在差异),筛选有效边界框。
Stage2: Difference Captions Generating
根据边界框信息在图像中绘制红框以突出显示差异区域。
使用 LLaVA-NEXT 基于区域内容生成差异描述。
Data Statistics
初始生成 118,000 对相似图像。
通过图像相似度过滤器筛选出 38,533 对高度相似的图像对。
使用差异区域生成器获得 117,779 条有效边界框信息(每对图像最多 5 个)。
最终通过差异描述生成器得到 12,688 个高质量 object replacement 实例。
Evaluation on Models trained with Img-Diff
本部分的评估显示了 Img-Diff 数据集对 MLLM 模型在多个基准测试上的提升效果,尤其在细粒度图像差异识别方面。通过微调后的模型,LLaVA-1.5 和 MGM 不仅在图像差异相关任务上达到了新的 SOTA 水平,还在综合视觉问答任务中表现出更强的整体能力。这表明 Img-Diff 数据集为 MLLM 的细节识别与图像理解提供了有效的增强。
评估设置: 将 Img-Diff 数据集与 LLaVA-1.5 和 MGM 的原始数据集结合,对模型进行微调,并在多个基准测试上进行评估。
MMVP 基准测试: 使用 object replacement 数据微调后,LLaVA-1.5-7B 和 MGM-7B 在 MMVP 上表现显著提升,超过 GPT-4V 和 Gemini,表明模型对图像细节差异的辨别能力增强。
Spot-the-Diff 基准测试:微调后的模型在 BLEU、METEOR、CIDEr-D 和 ROUGE-L 分数上表现提升,说明数据集增强了模型识别微小图像差异的能力。
Image-Edit-Request 基准测试:微调后,LLaVA-1.5-7B 和 MGM-7B 在描述图像编辑转换方面表现出色,达到了新的 SOTA 水平。
MLLM 基准测试: 微调后的 LLaVA-1.5-7B 和 MGM-7B 展现出整体性能提升,表明 object replacement 数据集不仅提升了图像差异识别,还提升了模型的综合视觉能力。
Ablation Studies 消融实验
实验目的: 研究不同过滤阈值对数据集和模型性能的影响。
IS(图像相似度): 相似度低会引入无效实例,降低数据质量。
BITM(边界框图文匹配): 提升阈值略微提升性能,保留与物体替换更相关的边界框。
CS(描述相似性)和 CITM(描述图文匹配): 提高阈值显著提升模型性能,说明较高过滤强度带来更高数据质量。
结论: 更强的过滤强度提升数据有效性,但会减少实例数量。最终选择模型 (3) 的阈值以兼顾数据质量和数量。
Evaluation of Data Quality and Diversity
数据质量与多样性评估结果表明,Img-Diff 数据集在涵盖常见和少见物体类别方面表现优异,并且通过多重评估指标验证了其高质量的描述和差异生成策略。
数据质量评估
随机选取 1,000 个“物体替换”实例,通过“边界框差异”、“内容描述准确性”和“差异描述准确性”三个指标评估数据质量。
边界框差异评估物体差异显著性;内容描述准确性评估描述与子图的匹配度;差异描述准确性评估差异描述的准确度。
图 6 显示了高质量的数据集:80.1% 内容描述准确,超过 70% 的差异描述完全准确。
数据多样性评估
通过物体类别、唯一物体替换对数量和物体名称出现频率评估数据多样性。
覆盖 1,203 种物体类别、3,680 对唯一物体替换对,确保高频常见物体与广泛覆盖的少见物体的多样性。
The “Object Removal” Exploration
目标: 增强模型对物体存在与否的识别能力。
通过“物体移除”数据微调,LLaVA-1.5-7B 的综合性能提升至 3.91%,MGM-7B 略微下降,可能因其原始数据中已有相应数据。
结论: 当微调数据不足时,“物体移除”数据可作为有效补充。
Conclusion
提出 Img-Diff 数据集,通过物体替换生成相似图像对,专注于图像特定区域的差异描述。
使用差异区域生成器和描述生成器确保描述的准确性,解决了以往数据集中差异描述不全面的问题。
微调后的 LLaVA-1.5-7B 和 MGM-7B 在多个基准测试上达到了高性能。
本研究展示了对比数据驱动方法在增强 MLLM 图像识别能力中的有效性。

