
这篇文章的主要贡献是介绍了LLaVA-NeXT-Interleave模型,该模型旨在解决多模态模型在多图像(multi-image)、多帧(视频)、3D场景和单图像任务上的通用适应性。其核心创新在于提出一种交错(interleave)数据格式,使模型能够在多种视觉任务间灵活适应,并实现跨任务的迁移能力。
主要贡献
- 交错数据格式的通用性
作者提出使用图像-文本交错的格式作为统一的数据模板,不论是单图像、多图像、视频多帧还是3D多视角数据,都可以采用该格式处理。这一统一模板使模型在不同任务中表现出一致性和高适应性,打破了以往每种任务单独设计模型的局限性。
- M4-Instruct数据集的构建
为支持多任务学习,作者构建了包含1177.6k样本的M4-Instruct数据集,涵盖4个主要领域(多图像、视频多帧、3D多视角、单图像),共14个任务和41个数据集。这个数据集成为训练多模态模型的高质量数据来源,并通过丰富的数据覆盖实现更强的模型泛化能力。
- LLaVA-Interleave Bench评估基准
为了评估模型在多图像任务上的表现,作者引入了LLaVA-Interleave Bench,这一基准包括7个新收集的评估任务和13个现有数据集,提供了多种视觉任务的评估标准,使得模型可以在跨领域和跨任务中进行比较。
- 多任务迁移与创新能力
通过多任务联合训练,LLaVA-NeXT-Interleave展现了跨任务迁移的潜力,如从单图像任务到多图像任务的迁移,以及从图像任务到视频任务的迁移。这些“新兴能力”表明,模型在训练过程中发展出了一定的泛化能力,能够在推理时适应新的任务和场景。
Abstract & Introduction
研究背景: 现有开源的大型多模态模型多集中于单图像任务,缺少对多图像场景的泛化能力,且早期研究无法支持跨场景应用。
模型介绍: LLaVA-NeXT-Interleave模型旨在统一处理多图像、多帧(视频)、3D多视角和单图像任务。它通过一种通用的交错数据格式模板实现跨模态和跨任务的泛化能力。
数据集: 编制了M4-Instruct数据集,包含117.76万条数据,涵盖了14个任务和41个数据集,支持多模态模型的多任务学习。
评估基准: 创建了LLaVA-Interleave Bench评估基准,用于全面评测多图像任务表现。
实验结果: 模型在多图像、视频和3D任务上表现领先,并保持单图像任务性能,展示了新兴的跨模态迁移能力。
Related Work
Interleaved Image-text Training Data
交错格式赋予LMMs多模态上下文学习(ICL)和指令跟随能力。ICL能力通过在提示中插入图像-文本示例实现少样本学习。重要模型包括Flamingo(首次展示ICL)和MIMIC-IT(生成多模态样本的 automatic pipeline)。此外,VPG-C和M4-Instruct提供了丰富的多图像数据集以扩展多场景覆盖。
Interleaved LMMs
代表性模型GPT-4V和Gemini表现出较强的多图像应用能力。
ICL性能已被用于多模态预训练的评估。
LLaVA-NeXT-Interleave 通过单一模型实现了多图像、视频、3D和单图像的多场景处理,展示了跨场景的任务组合能力。
Interleaved Benchmarks
多个基准被用来评估LMMs的多图像能力,包括NLVR2用于日常VQA、DEMON编制了大量多样性数据集。
本文提出的LLaVA-Interleave Bench基准包含高质量样本,涵盖特定和通用场景,分为in-domain 和 out-domain schemes。
Interleaved Multi-image Tasks & Data 交错多图像任务与数据
Task Overview
此部分提出了使用交错格式处理多种任务的框架,将多图像和单图像任务统一为一个模型的输入方式,为多模态任务的跨场景应用提供了创新性的解决方案。
多图像场景: 通过交错的视觉-语言输入处理多张图像的任务,包括差异识别、图像编辑等现实应用任务。
多帧场景: 使用视频的多帧序列来保持时间信息,涉及视频字幕生成和视频VQA任务。
多视角场景: 通过不同视角的图像反映3D环境的空间信息,包括3D场景和具身VQA任务。
多片段场景: 将单图像分割成多个低分辨率片段以提高视觉编码效率,适用于传统的单图像任务。
M4-Instruct
M4-Instruct数据集的设计和LLaVA-Interleave Bench评估基准的引入为LMMs在多场景中的全面评估提供了支持。通过域内 in-domain 和域外 out-domain 任务的划分,能够更清晰地考察模型的泛化和适应能力。
数据集构建: M4-Instruct数据集包含117.76万条实例,涵盖多图像、多帧、多视角和多片段四种场景,支持14个任务和41个数据集,增强了模型在多图像任务中的表现和多样化能力。
数据源与标注: 多图像数据源自公开数据并转化为统一格式,新增“真实世界差异”等三项任务;视频数据从LLaVA-Hound等数据集收集;3D数据涵盖室内外场景,单图像数据则随机抽取用于保持单图像能力。
评估基准: LLaVA-Interleave Bench包含17K条数据的13个多图像任务,分为域内(12.9K)和域外(4.1K)评估,以测试模型在见过和未见过任务上的表现。
可以将域内场景(in-domain)理解为模型在训练过程中“见过”的任务场景,即直接使用过的训练数据。
域外场景(out-domain)则是指模型在训练过程中未曾接触过的场景或任务,即没有直接使用过的训练数据。这些任务与训练数据不重叠,用于测试模型在完全新环境下的泛化能力
Interleaved Visual Instruction Tuning 交错视觉指令调优
这部分内容展示了LLaVA-NeXT-Interleave的三个关键技术,强调了基于单图像模型的训练扩展、多格式数据支持和多任务数据融合的创新之处,使模型在应对多样化视觉任务时更具灵活性和准确性。
继续训练单图像模型
基于经过第一阶段的图像-字幕预训练和第二阶段的单图像微调的LLaVA-NeXT-Image模型,使用 M4-Instruct数据集执行交错的多图像指令调优

通过以预训练的单图像模型作为基础,模型能更好地适应多图像任务的推理需求,特别是那些需要复杂推理的任务。
Mixed Interleaved data formats during training
使用前置格式和交错格式来增强模型的灵活性和鲁棒性,使模型能够适应不同的输入格式,从而支持更灵活的推理。
前置格式 In-the-front format
将所有 image tokens 放在 prompt 之前,同时在文本中保留
- 举例说明理解
prompt:
看一下图片1和图片2,描述它们之间的不同之处。
前置格式如下:
1 | image1 tokens |
这种方式下,模型在处理输入时会先看到所有的图像,然后再看到文本提示。占位符⟨image⟩仍然会留在文本中,表明之前的图像内容。
交错格式 interleaved format
将 image tokens放在原来的位置,即
- 举例说明理解
prompt:
看一下图片1和图片2,描述它们之间的不同之处。
交错格式如下:
1 | 看一下 image1 tokens 和 image2 tokens, 描述它们之间的不同之处。 |
这更贴近实际场景中图像和文本的自然交互顺序。
多场景数据组合
利用四种任务的指令调优来提供互补信息,提高模型在每个单项任务上的性能,超越传统上仅使用单一数据源的微调方法。
Experiments
Settings
此部分设计了全面的评估方案和详细的实现配置,确保LLaVA-NeXT-Interleave在多个复杂场景下的性能得到全面、客观的验证。
评估场景: 在多图像、多帧视频、多视角3D和单图像四种交错场景下测试模型性能,涵盖全面的领域和评估标准。
评估基准与指标: 针对不同场景,使用多种数据集进行评估;视频评估还包含五个质量指标,3D评估则加入了新测试集,确保了评估的广泛性和准确性。
实现细节: 模型使用Qwen 1.5作为语言模型,视觉编码器采用SigLIP-400M,以两层MLP完成投影。
Main Results
此部分展示了LLaVA-NeXT-Interleave在四类场景下的广泛适应性和强劲性能,表明其在多模态任务中的领先水平和多任务迁移能力。
多图像任务: LLaVA-NeXT-Interleave在域内和域外任务上均优于其他模型,特别是在域外任务中表现出色,表明其具有较强的泛化能力。
多帧(视频)任务: 尽管未专为视频任务设计,该模型在视频理解和时间推理方面表现出色,经过DPO训练后在VDD和VideoChatGPT基准上达到最先进水平。
多视角(3D)任务: 在3D任务上,模型无需额外的点云输入,通过多视角图像即可获得优异的3D场景理解表现,领先其他需要额外输入的模型。
多片段(单图像)任务: 通过增加高质量的单图像数据,模型保留了单图像任务性能,同时增强了指令跟随能力,使得单图像到多图像任务的迁移成为可能。
Ablations of Proposed Techniques 消融实验
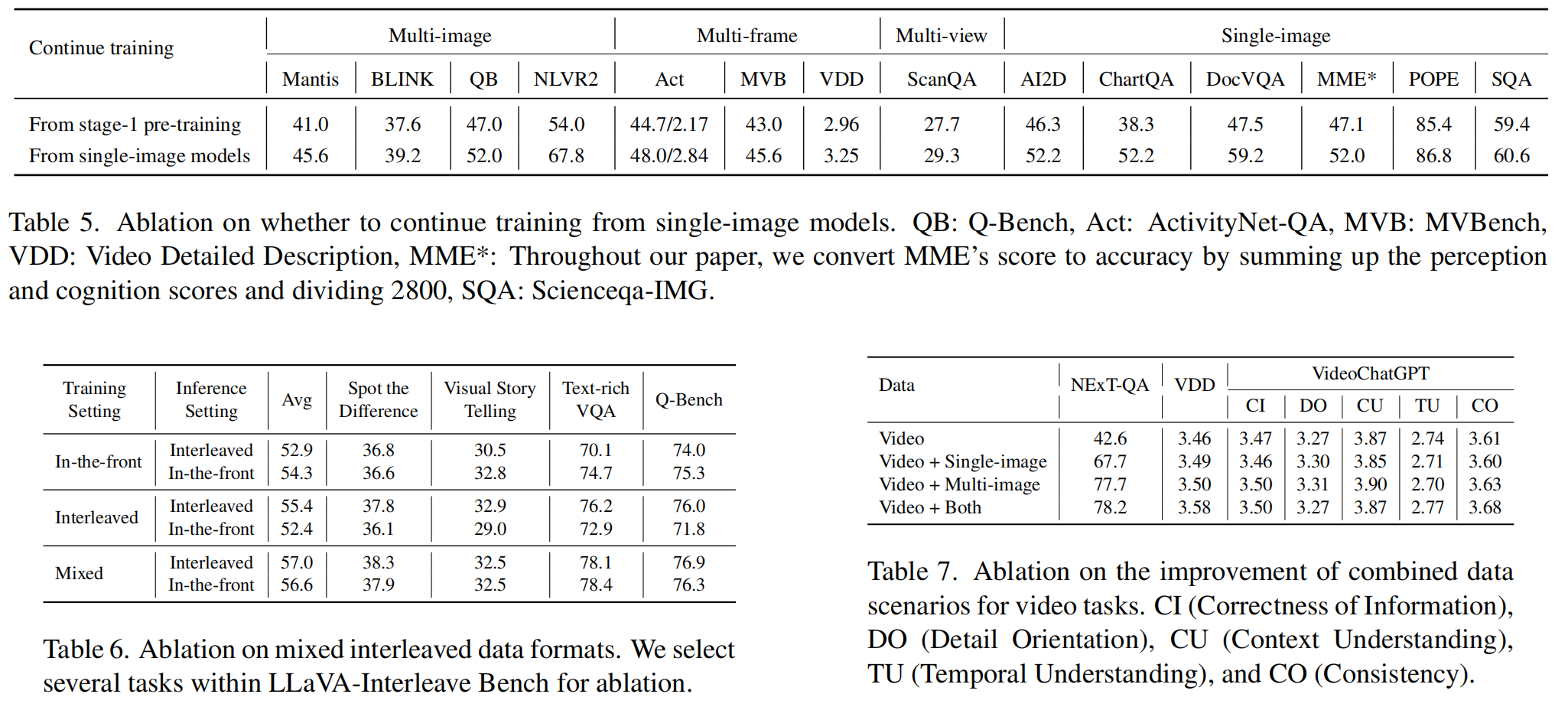
单图像模型初始化: 从单图像模型的第二阶段检查点进行初始化可以显著提高多图像任务的表现,表明基础模型的预训练阶段对后续任务性能有较大影响。
混合格式训练: 混合前置和交错格式的训练策略能够同时提高两种输入格式的适应性,使模型在应对不同格式输入时表现更好。
数据集成提升性能: 在视频数据的基础上逐步添加单图像和多图像数据,能够提升模型的整体性能,说明多数据源的整合对于模型的多任务学习具有重要作用。
Emerging Capabilities
任务迁移能力: 模型能够在未训练的任务间进行迁移,例如从单图像到多图像,以及从图像到视频的任务迁移。
现实应用场景: 模型表现出强大的泛化能力,能够适应绘画风格识别、PPT内容理解和跨文档VQA等实际应用场景。
Conclusion
读完啦 这里不重要~

