
在卷积神经网络(CNNs)中,归纳偏置 inductive biases是模型设计者预先引入的一种先验知识,它使模型能够更高效地从数据中学习。
卷积神经网络中的归纳偏置
在卷积神经网络(CNNs)中,归纳偏置 inductive biases是模型设计者预先引入的一种先验知识,它使模型能够更高效地从数据中学习。
归纳偏置在 CNNs 中尤为重要,因为它们帮助模型捕捉到数据的特定结构,尤其是在图像数据中,这种偏置使得 CNNs 在相对较小的训练数据集上也能够取得不错的效果。
在 CNNs 中,最常提到的两个归纳偏置是 locality 局部性和 translation equivariance 平移等变性。
1. 局部性(Locality)
CNNs 以滑动窗口的形式在图像上进行卷积操作,每次只关注图像的一小块区域。换句话说,CNN 假设图像中相邻像素之间有更高的相关性,因为在现实世界中,物体的局部特征往往在空间上紧密相邻。
例如,当我们在一张图片上看到桌子时,桌子旁边很可能会出现椅子。
这种局部相关性让CNN通过观察相对较小的区域,提取出关键特征并进行分类。
这种特性非常适合图像中的边缘检测、形状提取等任务,也帮助 CNN 有效减少参数数量,避免过拟合。
因此,局部性偏置使 CNNs 能够通过更少的计算资源来处理大量数据,同时保证良好的泛化能力。
2. 平移等变性(Translation Equivariance)
平移等变性指的是卷积运算对图像平移操作保持不变。具体来说,如果我们对输入图像进行某种平移操作,卷积后的特征图将保持相同的模式,只是特征的位置发生了相应的变化。
这意味着,模型不需要重新学习图像在不同位置出现的同一特征。
数学上可以这样描述:
$$
f(g(x))=g(f(x))
$$
其中,$f$ 代表卷积运算,$g$ 代表平移操作。无论先做平移还是先做卷积,结果都是一样的。
这种平移等变性赋予了 CNNs 对物体位置的鲁棒性,即不管物体位于图像的什么位置,模型都能识别出它的特征。
这与视觉系统在识别物体时的稳定性类似:无论物体在图像中移动到哪里,我们依然能认出它。这也是CNNs能在多种图像分类任务中表现优异的原因之一。
归纳偏置的优势:较少数据的高效学习
得益于 locality 和 translation equivariance,CNNs 能够通过相对较少的数据学习到有效的特征表示。CNN 将参数集中在局部区域,利用空间结构信息,大大降低了模型的自由度。这不仅减少了训练时所需的样本量,还提升了模型的泛化能力,使其能够处理复杂的图像任务。
举例来说,面对一个包含 1000 张猫的图片数据集,CNN 可以快速学会猫的耳朵、眼睛等局部特征,并且无论猫出现在图片的哪个角落,模型都能检测到这些特征。相比之下,如果使用没有这种归纳偏置的模型(比如全连接网络),模型需要看到更多的训练数据,才能够识别出相同的特征。
对比 Vision Transformer
与 CNN 不同的是,Vision Transformer(ViT)并没有显式地引入这些归纳偏置。ViT 模型处理图片的方式是将图像分割成固定大小的 patch,然后将这些 patch 当作序列输入 Transformer。这种方法使得 ViT 具有更大的灵活性,但也缺少了对局部性和平移等变性的利用。因此,ViT 在较小的数据集上往往表现不如 CNN。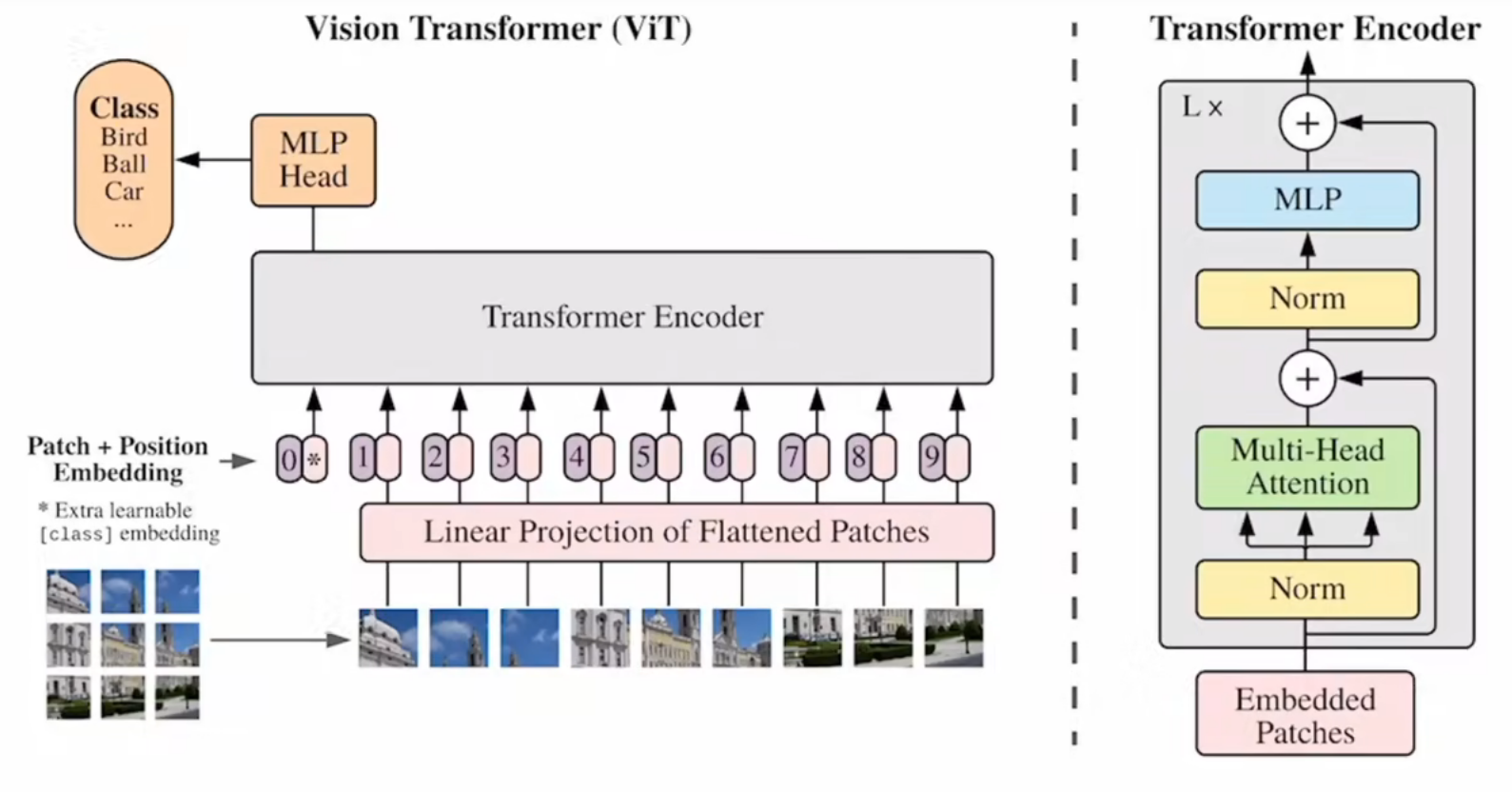
ViT需要更多的数据来弥补这一缺陷。没有局部性和平移等变性,ViT 必须从头学习如何理解空间关系和位置信息,这就导致了在数据不足时性能会显著下降。
结论
归纳偏置在 CNN中 的应用使得这些模型可以在较少的数据上获得良好的效果,尤其是对于那些图像数据较为稀少或标注较为昂贵的任务。局部性和平移等变性帮助 CNN 高效地学习图像中的特征,并且在分类任务中表现优异。虽然 Vision Transformer 在大型数据集上的表现已经超越了 CNN,但在小型和中型数据集上,CNN 仍然具有优势。

