
本次报告撰写人:WilliamZH
题目:202112,第24次CCFCSP
使用语言:C++
题目 1:序列查询
题目描述:
$A$ 是一个由 $n+1$ 个 $[0,N)$ 范围内整数组成的序列,递增,默认 $A[0]=0$。
定义查询 $f(x)$ 为:序列 $A$ 中 $≤x$ 的整数里最大的数的下标。
令 $sum(A)$ 表示 $f(0)$ 到 $f(N-1)$ 的总和。
对于给定的序列 $A$,求 $sum(A)$。
$1≤n≤200,n<N≤10⁷$
题解:
解法一:
$i$ 遍历 $0∼N-1$,再遍历序列 $A$,记最大值 $j$ 为下一次遍历起点。
时间复杂度$O(n+N)$,空间复杂度$O(n)$,期望得分100
1 |
|
解法二:
进一步优化效率。
若存在区间 $[i,j)$ 满足 $f(i)=f(i+1)=…=f(j-1)$,使用乘法运算 $f(i)×(j-i)$ 代替逐个相加。
时间复杂度$O(n)$,空间复杂度不变,期望得分100
1 |
|
题目 2:序列查询新解
题目描述:
$A$ 是一个由 $n+1$ 个 $[0,N)$ 范围内整数组成的序列,递增,默认 $A[0]=0$。
定义查询 $f(x)$ 为:序列 $A$ 中 $≤x$ 的整数里最大的数的下标。
如果 $A1,A2,⋯,An$ 均匀分布在 $(0,N)$ 的区间,那么就可以估算出:
$$f(x)≈\frac{(n-1)∙x}{N}$$
定义比例系数 $r=⌊\frac{N}{n+1}⌋$,用 $g(x)=⌊\frac{x}{r}⌋$ 表示估算出的 $f(x)$ 的大小。
用 $∣g(x)-f(x)∣$ 表示询问 $x$ 时的误差。
计算 $$ error(A)=\sum∣g(0)-f(0)∣+…+∣g(N-1)-f(N-1)∣$$
$1≤n≤10^5,n<N≤10^9$
题解:
解法一:
该解法同题一的解法一,计算 $f(x)$ 的同时计算每一个 $g(x)$。
但由于 $n$ 的范围增大,时间复杂度较高,导致超时。
时间复杂度$O(n+N)$,空间复杂度$O(n)$,期望得分70
1 |
|
解法二:
优化方法类似题一的解法二,在对 $f(x)$ 分组的同时,对相同的 $f(x)$ 内部再对 $g(x)$ 分组。
则该区间内的和为 $abs(f(i)-g(i))*gNum$,$gNum$ 表示该区间 $g(j)$ 的个数。
时间复杂度$O(n)$,空间复杂度不变,期望得分100
1 |
|
题目 3:登机牌条码
题目描述:
- 对于输入的被编码的数据,按照给定的表进行编码。
- 数据码字由以下数据按顺序拼接而成(如图所示):
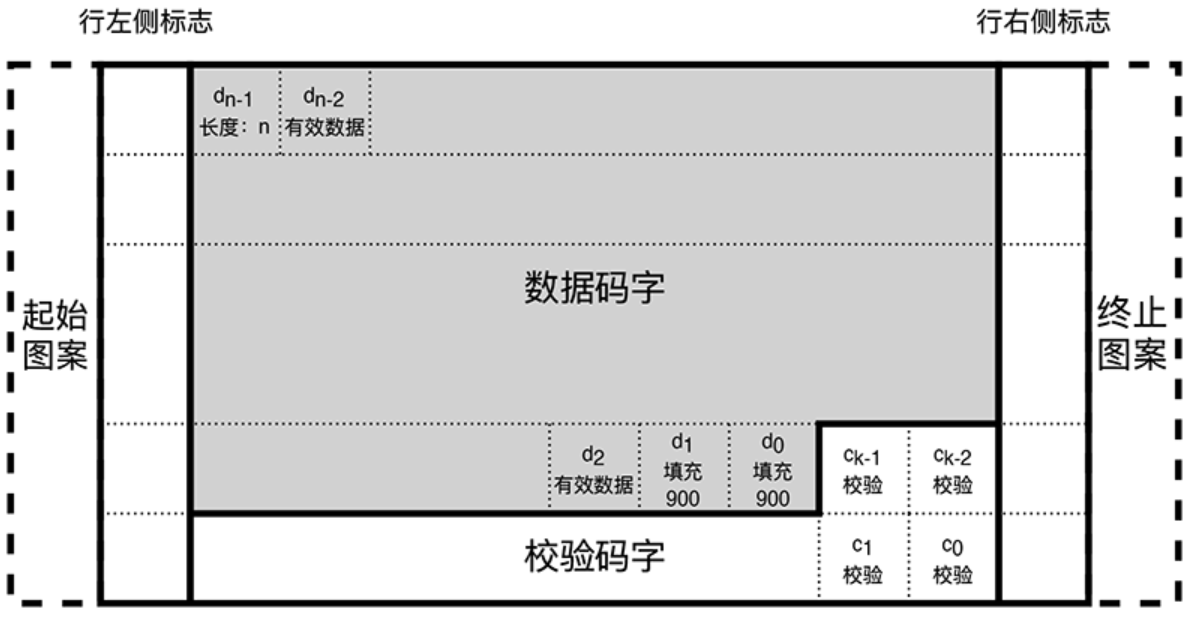
- 一个长度码字,表示全部数据码字的个数 $n$,包括该长度码字、有效数据码字、填充码字;
- 若干有效数据码字,是此前计算的码字序列;
- 零个或多个由重复的 $900$ 组成的填充码字,使得包括校验码字在内的码字总数恰能被有效数据区的行宽度整除。
- 校验码字按照如下方式计算:
取 $k$ 次多项式 $g(x)=(x−3)(x−3^2)…(x−3^k)$, $(n−1)$ 次多项式 $d(x)$,找到多项式 $q(x)$ 和不超过 $(k−1)$ 次的多项式 $r(x)$,使得 $x^kd(x)≡q(x)g(x)−r(x)$。
那么多项式 $r(x)$ 中 $x$ 的 $i$ 次项系数对 $929$ 取模后(取正值)的数字即为校验码字 $c_i$。
给定被编码的数据,计算出需要填入有效数据区的码字序列。被处理的数据中只含有大写字母、小写字母和数字。
题解:
解法一:
- 首先处理字符串,计算对应的数字:
用数组 $a$ 存储每一位数字,用 $pre$ 存储上一个字符的处理状态;数组最后一位下标若为偶数,则补充一个 $29$ 。 - 计算码字:
用数组 $d$ 存储有效数据的码字,有效数据的个数用 $dnum$ 存储。 - 计算校验码字个数:
$s==-1$ 时,$k=0$;否则 $k=pow(2,s+1)$。 - 计算填充码字:
总长度 $sum = dnum + 1 + k$,判断是否可被 $w$整除,以及填充多少个 $900$,同时 $dnum$ 相应增加。
不考虑校验码字,至此即可得40分。
解法二:
接着解法一的四步,计算校验码字。
5. 计算校验码字:
- 预处理公式:等式两边同时对 $g(x)$ 取余,则 $x^kd(x) mod g(x) ≡ -r(x) mod g(x)$。即求 $x^k d(x) mod g(x)$ 后取反。
- 避免数据溢出,需在计算过程中取模。
- 计算 $g(x)$ 时考虑到每一次多项式乘以的因子都是 $(x−a)$ 的格式, 所以可以把 $A*(x−a)$的多项式相乘转化为 $xA−aA$ 的格式。 $x*A$ 可以通过整体移项实现;在移项后,原本在 $x_i$ 的系数成为 $x_{i+1}$ 的系数。
- 首先, $t$ 被初始化为 $-3$,然后 $g[0]$ 被初始化为 $1$,表示 $g(x)$ 中 $x^0$ 的系数为 $1$。
然后,外层循环 $i$ 从 $1$ 到 $k$,每次循环将 $t$ 乘以 $3$,表示将多项式中的 $x-3$,$x-3^2$ 等因子依次处理。内层循环 $j$ 从 $i - 1$ 到 $0$,对于每个 $j$,使用递推的方法计算 $g(x)$ 中 $x^j$ 的系数。具体来说,根据多项式的乘法规则,$x^j$ 可以由 $x^{j-1}$ 和 $x^j$ 两项乘以 $-3^i$ 而得到,即:
$$
x^j = (x^{j-1} \cdot (-3^i)) + (x^j \cdot (-3^i))
$$
这个式子中,$x^{j-1}$ 代表 $g(x)$ 中 $(x - 3^{i-1})$ 的贡献,而 $x^j$ 代表 $g(x)$ 中 $(x - 3^i)$ 的贡献。因此,我们需要把这两个贡献相加,得到 $g(x)$ 中 $x^j$ 的系数,即 $g[j + 1]$。这个系数的初始值为 $0$,每次递推时先加上原来的值,再加上 $g[j] \cdot t$ 即可更新。
最终,当 $i$ 循环 $k$ 次后,$g$ 数组中存储的就是 $g(x)$ 的各项系数。具体来说,$g[x]$ 中存储的是 $g(x)$ 中 $x^{k-x}$ 的系数。 - 将除法多项式 $D(x)$ 对多项式 $g(x)=(x-3)(x-3^2)…(x-3^k)$ 取模,并将余数存储在 $D(x)$ 中。其中,$D(x)$ 的各项系数存储在数组 $D$ 中,$g(x)$ 的各项系数存储在数组 $g$ 中,$k$ 是 $g(x)$ 的最高次幂次数,$mod$ 是一个取模变量。
首先,将 $D(x)$ 的常数项系数初始化为 $n$,即 $D_0=n$。然后,将 $D(x)$ 的各项系数从数组 $d$ 中复制到数组 $D$ 中,通过循环实现:其中,$dnum$ 表示 $d(x)$ 的最高次幂次数。1
2for (int i = 1; i <= dnum; i++)
D[i] = d[i - 1];
接下来,对于 $D(x)$ 的每一项系数 $Di$,都通过 $g(x)$ 进行一次带余除法。具体来说,使用 $Di$ 乘以 $g(x)$ 的各项系数 $gj$,得到一个新的多项式 $Dix^jg(x)$,将其减去 $D(x)$ 的前 $i$ 项系数 $D0,D1,\ldots,D{i-1}$ 的线性组合,并将差存储在 $D{i+j}$ 中:这里用到的余数公式是:1
2for (int j = 1; j <= k; j++)
D[i + j] = (D[i + j] - D[i] * g[j]) % mod;
$$
f(x) \equiv g(x) \cdot q(x) + r(x) \pmod{m},
$$
其中 $f(x)$ 是被除多项式,$g(x)$ 是除数多项式,$q(x)$ 是商多项式,$r(x)$ 是余数多项式,$m$ 是取模变量。将这个公式代入上述代码,可以发现 $D(x)$ 对 $g(x)$ 取模后的余数 $r(x)$ 实际上就是 $D_ix^jg(x)$ 减去 $D(x)$ 的前 $i$ 项系数的值,再对 $m$ 取模。
最后,将 $D(x)$ 的前 $i$ 项系数赋值为 $0$,以保证在之后的计算中不会重复使用:
D[i] = 0;
当两个循环都运行完毕后,$D(x)$ 中存储的就是 $D(x)$ 对 $g(x)$ 取模的余数。
期望得分100。
1 |
|
题目 4:磁盘文件操作
题目描述:
定义一组可能互斥的程序操作,如写、删、恢复这些操作是互斥的。写操作只能写到被自己占用磁盘空间、删除只能目标空间全被自己占用、恢复则只能上次自己占用的;读取也读取自己占用的。
给定很多这样的操作,同时在一块共享的磁盘空间上进行运行,根据上面操作的定义,其操作结果成功与否。比如写成功到什么位置(-1 表示一个也没写入),删除恢复成功与否(用 OK, FAIL 表示)。
题解:
解法一:
直接模拟。
- 写入操作:从左往右依次执行,直到第一个不被自己占用的位置。除了第一个点就被其他程序占用以外,必然会写入。遇到自己占用,则覆盖。
- 删除操作:同时整体进行,要求所有位置都被目前程序占用。要么全删,要么不做任何更改。
- 恢复操作:同时整体进行,要求所有位置都不被占用,且上次占用程序为目前程序。要么全恢复,要么不做任何更改。遇到自己占用,则不做任何更改。
- 读入操作:读取占用程序和数值,若未被占用,则输出 0 0。
可通过25%数据。
1 |
|
解法二:
离散化+线段树。
我们假设一个位置未被占用和被 $id$ 为 $0$ 的程序占用是等价的。
- 写入操作:划分为找到写入右边界和直接写入两个操作。
直接写入操作就是直接的线段树区间修改, 而划分操作需要知道该区间被占用的位置是否属于将要写入的 $id$。 不妨将这个量设为 $id1$。 - 删除操作:划分为判断是否可删和直接删除两个操作。
直接删除操作就是直接的线段树区间修改, 而判断是否可删需要知道该区间所有的位置是否属于将要写入的 $id$。 不妨将这个量设为 $id2$,注意 $id1$ 与 $id2$ 的区别——是否允许包含未被占用的程序。 - 恢复操作:划分为判断是否可恢复和直接恢复两个操作。
该操作与删除操作类似,不过需要注意的是判断时需要判断目前占用的 $id$ 和上次被占用的 $id$。 - 读取操作:划分为查询占用程序 $id$ 和查询值两个操作。
该操作是相对比较质朴的单点查询,当然也可以处理为区间。
线段树
需要维护的量: - 值 $val$:每个节点代表取值的多少,若左右子节点不同则设为一个不存在的值。因为我们是单点查询,所以不用担心查询到不存在的值的问题。
- 被占用位置程序 $id1$:
- 若左右子节点都未被占用,则该节点标记为未占用(0);
- 若左右子节点中存在不唯一节点,则该节点标记为不唯一(-1);
- 若左右子节点中一个节点未占用,则该节点标记为另一个非空节点的标记;
- 若左右子节点都非空且相等,则该节点标记为任意一个子节点;
- 若左右子节点都非空且不等,则该节点标记为不唯一;
- 被占用位置程序 $id2$:为了方便进行讨论,将未被程序占用节点视为被 $id$ 为 $0$ 的程序占用。
- 若左右子节点中存在不唯一节点,则该节点标记为不唯一。
- 若左右子节点相等,则该节点标记为任意一个子节点;
- 若左右子节点不等,则该节点标记为不唯一;
- 上一次被占用程序 $lid$:与 $id2$ 相同。
- 若左右子节点中存在不唯一节点,则该节点标记为不唯一。
- 若左右子节点相等,则该节点标记为任意一个节点;
- 若左右子节点不等,则该节点标记为不唯一;
ls 和 rs 是代表节点编号的变量。在这段代码中,通过位运算的方式将 o << 1 和 ls | 1 分别表示为左右孩子节点的编号。具体而言,ls = o << 1 表示将 o 左移一位,并将结果赋值给 ls;rs = ls | 1 表示将 ls 二进制最低位设置为 1 ,作为右孩子的编号。这样做的好处是可以避免直接写出具体的左右孩子编号,在二叉树结点数量变化时保证程序稳定性。
通过离散化解决空间问题。
时间复杂度 $O(klogk)$,期望得分$100$。
1 |
|
题目 5:极差路径
题目描述:
给定一颗树,定义一条路径是被推荐的,当且仅当:
$$min(x,y)-k_1≤minP(x,y)≤maxP(x,y)≤max(x,y)+k_2$$
其中,$minP(x,y)$表示从 $x$ 到 $y$ 的简单路径上的编号最小值,$maxP(x,y)$表示从 $x$ 到 $y$ 的简单路径上的编号最大值。
$(x,y)$ 和 $(y,x)$ 被视为同一条路径。
求被推荐的路径条数。
$1≤n≤5×10^5,0≤k_1,k_2≤n$
题解:
解法一:
dfs暴力搜索。
时间复杂度 $O(n^3)$,期望得分12。
1 |
|
解法二:
点分治+三位数点。
定义一个点的权值为它的最大子树的大小。
以重心为根,最大子树的大小,必然不大于树中总点数的一半。
每次操作统计所有与重心相连接的路径,再将重心消除,形成一个森林,再递归操作下去。
假设当前处理的根节点为 $u$,从 $u$ 开始dfs一遍得到从 $u$ 到各点路径的$min$和$max$,用三元组$(v,minv,maxv)$表示。
合法路径的条数满足$$v_1<v_2,
v_1-k_1≤min(minv_1,minv_2),max(maxv_1,maxv_2)≤v_2+k_2$$的三元组$(v_1,minv_1,maxv_1),(v_2,minv_2,maxv_2$)的对数。
为降低时间复杂度,选择可持久化线段树。
按照点的编号将三元组排序后,按编号从小到大依次处理。
$v_1−k_1≤min(minv_1,minv_2)$可以拆分成 $v_1−k_1≤minv_1$ 和 $v_1−k_1≤minv_2$,前面的式子可以直接判断。
同样的,将 $max(maxv_1,maxv_2)≤v_2+k_2$ 拆分成 $maxv_1≤v_2+k_2$ 和 $maxv_2≤v_2+k_2$,后面的式子可以直接判断。
处理 $v_1−k_1≤minv_2$ 和 $maxv_1≤v_2+k_2$ :
在 $root[v_1−k_1]$ 线段树的 $maxv_1$ 位置进行$+1$操作。然后枚举到 $v_2$ 时,对应的以 $v_2$ 为大端的路径条数就是 $root[minv_2]$ 中区间 $1⋯v_2+k_2$ 的和。
时间复杂度 $O(nlogn)$,期望得分$100$。
1 |
|

